48
시맨틱 웹에 대해 많이 들었지만 아직도 정확히 무엇인지 확신 할 수 없습니다. 우리가 지금 알고있는 웹과 어떻게 다른가?시맨틱 웹이란 무엇입니까?
시맨틱 웹에 대해 많이 들었지만 아직도 정확히 무엇인지 확신 할 수 없습니다. 우리가 지금 알고있는 웹과 어떻게 다른가?시맨틱 웹이란 무엇입니까?
우리가 지금 알고있는 웹과 어떻게 다릅니 까?
지금 HTML + CSS는 구조와 프리젠 테이션에 더 중점을두고 있습니다. 의미는을 의미하는 을 의미합니다. 시맨틱 웹에서는 객체의 의미 (의미)와 객체 간의 관계의 의미를 설정하기 위해 공유 된 ontologies을 사용합니다. 가장 잘 알려진 온톨로지는 FOAF 및 Dublin Core입니다.
일반적으로 의미는 RDF 또는 OWL과 같은 특수 언어로 표시됩니다. RDF는 eRDF 또는 W3C의 RDFa을 사용하여 XHTML에 임베드 될 수 있습니다.
eRDF/RDFa 대신에 구조화 된 대체 방법은 microformats입니다.
더 읽기에 : 우리가 내용 등, <b>, '<pre>을 표시 태그가 콘텐츠에 대한 의미를 암시해서는 안 방법을 설명 마크 업 태그가 HTML 페이지와 현재 http://en.wikipedia.org/wiki/Semantic_web
.
의미 론적 웹의 개념은 문서가 내용에 의미를 부여하는 XML 태그를 포함한다는 것입니다. 예 : <person><firstname>. 훌륭한 아이디어는 CSS가 이와 같은 문서 형식을 지정할 수 있지만이 문서에서 의미있는 정보를 쉽게 추출 할 수 있다는 것입니다.
HTML 요소가 의미 론적 의미가 없다는 것은 일반적인 오해입니다. HTML은 문서 구조와 관련하여 요소의 의미만을 다룹니다. HTML은 데이터 중심의 의미론이 아닌 문서 중심의 의미 체계를 가지고 있습니다. –
HTML은 의미 론적 의미가 전혀 없다고 말하지 않았으므로, 내용에 대해 의미가 없음을 의미한다고 말했습니다. HTML이 구조적이라는 것은 렌더러에 대한 의미가 있음을 의미합니다.HTML은 콘텐츠 자체와 불가분합니다. – AnthonyWJones
대문자 S를 사용하는 시맨틱 웹은 RDF입니다. XML의 사용은 부수적 일뿐입니다. – hsivonen
웹 2.0과 비슷하게 사람들의 관심을 끌기위한 인기있는 단어입니다.
예. 앞으로는 컨텐츠가 많은 선을 허용하는 프리젠 테이션에서 분리 될 것입니다.
현실 사실은 주인의 현실성과 권위에 따라 주관적입니다.
다른 말로하면 사용자는 지금과 크게 다르지 않습니다.
가장 좋은 설명은 예제입니다. 무연 차량으로 2.0 리터보다 작은 엔진으로 웹에 광고 된 모든 차량에 googling을 시도해보십시오. 무연 차량으로 mp3 연결이 가능하며 내 집에서 대중 교통으로 쉽게 접근 할 수있는 쇼룸에서 볼 수 있습니다.
Google은이 쿼리를 실제로 지원하지는 않습니다. 여러 가지 검색을 수행하고 결과를 상호 연관시켜야합니다. 시맨틱 웹에서 자동차 판매용 제품에 관심을 표명하고 제약 조건을 추가 할 수 있습니다. 모든 결과가 유용 할 것입니다. 하나 이상의 UI가이를 가능하게 할 수도 있고, 일부는 전문화되거나, 다른 일부 UI는 완전히 일반화 될 수도 있습니다.
또 다른 예로 예를 들어 다이어트 콜라의 인기 또는 인구 집단의 걷기와 같은 인구 집단의 임상 비만 수준을 비교하면 일반적으로 한 곳에서 저장되지 않는 물건 차트를 만듭니다. 이 경우에는 웹 브라우저를 전혀 사용할 수 없지만 something more like Excel을 사용할 수 있습니다.하지만 시맨틱 웹은 HTTP를 통해 액세스 할 수있는 데이터를 찾고 조작하기위한 도구 (SPARQL, RDF)를 제공합니다.
Bravax가 지적한 점은 완전히 사실이 아니기 때문에 많이 바뀌지는 않을 것입니다. 단지 더 유용하고 우수한 매시업 웹 사이트를 얻을 수 있습니다. 또는 당신은 당신이 오늘 전에 웹과 관련이 있다고 생각하지 않았던 많은 것을하고 있음을 알게 될 것입니다.
현재 웹에는 Animated GIF, Flash, Silverlight, DHTML 등등 같은 일을하는 많은 대안이 있습니다. 시맨틱 웹에 데이터를 저장하려면 다양한 도구와 형식이 있어야합니다. RDFa는 마이크로 포맷의보다 일반적인 유형이지만, 전체 데이터베이스의 provide a dump은 SPARQL endpoint이며, 마이크로 포맷 또는 독점 HTML 구조를 사용하고 add a transformation을 사용하면 다른 경우에 적합한 많은 도구가 제공됩니다.
그래도 Vartec은 부분적으로 올바르므로 RDFa와 eRDF를 사용할 수 있지만 데이터를 게시하는 데는 다른 많은 기능을 사용할 수도 있습니다.
시맨틱 웹과 Linked Data이라는 또 다른 단순한 개념 사이에는 오버랩이 많이 있습니다. 서로 어떻게 연관되어 있는지는 분명하지 않지만 시맨틱 웹 도구와 기술이 필요하기 전에 Linked Data 웹이 필요한 것입니다. Linked Data는 데이터에 관한 것이며, Semantic Web은 데이터 처리, 추론 및 신뢰 신뢰성과 같은 문제 처리에 관한 것입니다. 근본적으로 the technology stack의 아래쪽 몇 개의 레이어.
검색 엔진에 SPARQL 쿼리를 입력하는 최종 사용자에게 행운을 빈다. – hsivonen
나는 사용자가 SQL을 입력 할 때마다 SPARQL을 자주 입력 할 것이라고 생각한다. 가끔은 Excel 스프레드 시트에 SQL이 얼마나 많이 포함되어 있는지보기 힘들 것입니다. –
내 검색 엔진 예제는 SPARQL을 언급하지 않았습니다 .... –
시맨틱 웹은 정말 간단한 생각입니다. (모든 좋은 것들처럼)
웹은 현재 그들 사이에 링크가있는 문서로 구성됩니다. Google은 컨텍스트를 사용하고 링크 내에 텍스트를 앵커링하여 링크의 의미를 파악하고이를 기반으로 데이터를 검색 할 수있는 엔진을 구축하는 등 상당한 성과를 거두었습니다. 즉, Google은 링크의 의미 의미가 무엇인지 추측합니다.
시맨틱 웹 아이디어는 "이 링크를 입력하면 어떻게 될까요?" 웹상의 모든 사실은 주소 (URI)를 얻고 관계 (도 URI)에 의해 다른 사실 (URI도)에 연결됩니다. 관계 그룹을 "온톨로지"라고합니다.
그래서 그 대신 페이지 B에 대한 페이지 A를 링크, 현재 웹에서처럼, 시맨틱 웹의 링크는 더 같은 유형의 링크 URI B에
URI 링크 URI C.
무엇이든 URI를 가질 수 있습니다. 사람들은 URI를 가질 수 있습니다. 보통 FOAF라고하는 일련의 관계를 사용하여 설명합니다. 자, Jeff Atwood의 URI가 http://codinghorror.com/foaf.xml이라고 가정 해 보겠습니다. 당신은 말할 수 :
< http://codinghorror.com> < http://xmlns.com/foaf/0.1/homepage> < http://codinghorror.com/foaf.xml>
즉, http://codinghorror.com는 http://codinghorror.com/foaf.xml의 내용으로 표시 사람의 홈페이지입니다.
이제 컴퓨터에서 이러한 관계를 읽고 쿼리 할 수 있으므로 컴퓨터를 통해 즉시 컴퓨터에서 수행 할 수있는 데이터베이스로 웹을 전환 할 수 있습니다. Semantic Web 쿼리 언어는 SPARQL이며 체크 아웃 할 가치가있다.
시맨틱 웹은 상호 연결된 데이터가 HTTP를 통해 RDF 트리플로 게시되는 분산 정보 시스템입니다. RDF 트리플은 주체, 술어 및 객체로 구성되지만 객체의 자연어에 대한 데이터 유형 및 주석과 같은 다른 속성이 첨부 될 수 있습니다.시맨틱 웹에서 URI는 식별자 및 네트워크 리소스의 주소로 사용됩니다.
웹은 문서 및 응용 프로그램 인터페이스의 분산 된 정보 시스템이기 때문에 웹과 다릅니다.
시맨틱 웹은 월드 와이드 웹 (World Wide Web)의 발명가 인 팀 버너스 리 (Tim Berners-Lee)가 실제로 웹을 의도 한 것입니다. 즉, 상호 연결된 데이터의 글로벌 그래프입니다. a generalization of a social graph입니다. 소셜 데이터 (FOAF과 같은 어휘 포함) 및 다른 유형의 기계 이해 가능 데이터를 사용하고 서로 연결할 수 있습니다. 이 infortmation을 기계에 설명하는 표준 형식은 자원 설명 형식 (RDF)과 웹 온톨로지 언어 (OWL)입니다. DBPedia이라고하는 위키피디아의 RDF 버전을 비롯하여 웹에 이미 많은 인코딩 된 데이터가 있습니다.
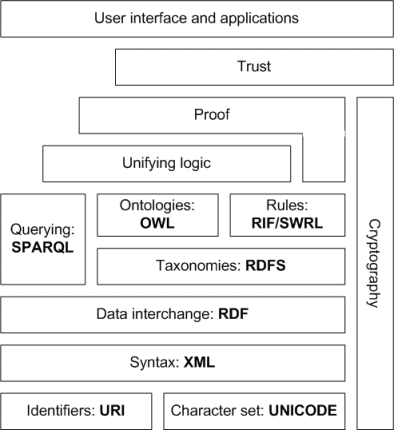
시맨틱 웹은 문서뿐만 아니라 인간도 문서 간의 링크의 중요성을 이해할 수 있다는 점에서 오늘날의 웹과 다릅니다. 이는 신뢰할 수있는 출처의 정보를 연구하는 것을 포함하여 정보 처리 업무의 자동화를 용이하게합니다. The full SemWeb stack에는 암호화, 증명 시스템 및 신뢰 네트워크가 포함됩니다.
시맨틱 웹은 WWW 상단의 시맨틱 (의미있는) 계층입니다. 그것은 반 구조화 (RDF), 자체 기술 (OWL을 사용하는 온톨로지) 및 자원 발견 (SPARQL)을 허용합니다.
시맨틱 웹은 "오픈 월드"가정을 전제로 작동합니다. 진술되지 않은 것은 그것이 존재하지 않는다는 것을 의미하는 것이 아니라 단지 "알려지지 않은"것입니다. 이것은 MySQL 외에도 RDBMS에서 사용되는 논리와 근본적으로 다른 논리입니다. - 뭔가 빠졌을 경우 존재하지 않는다 - "Closed World"가정. Prolog 및 DATALOG는 Close World 논리의 좋은 예입니다.
실제로 일어나는 일을 배우려면 Description Logic에있는 기초를 살펴야합니다. 설명 논리에 대한 개요는 여기에서 확인할 수 있습니다. http://www.inf.unibz.it/~franconi/dl/course/
RDF에 대해 자세히 알고 싶으면 RDF Primer을 읽어보십시오. RDF Semantics은 또 다른 립 - 울리는 읽기입니다.
연구원은 기본적으로 시맨틱 웹의 "의미"일부 포기하고 링크 된 데이터에 집중하기로 결정했다 - 우리가
Tim Berners-Lee 설명 더 인터넷 대역폭을 ;-) 낭비 할 수 있도록 RDF를 탐색 할 수 트리플을하는 방법
세 가지 정신 이동 :
"중요하다
우리는 단어 그래프를 사용할 수 있습니다, 지금, 웹에서 구별 할 수 있습니다.
나는이 그래프를 시맨틱 웹이라고 불렀지 만 아마도 거대한 글로벌 그래프 였어 야했다! WWWW보다 더 나쁜가요? ;-) 오랫동안 "시맨틱 웹"용어가 확립 된 것은 아니며, 나는 그것을 변경하기를 제안하지 않고있다. 그러나 그것이있는 그래프에 대해 생각해 봅시다. RDF 파서가 DOM 트리를 생성하는 동안 RDF 파서는 메모리에 RDF 그래프를 만듭니다.
시맨틱 웹은 World Wide Web의 고유 한 디자인 결함을 복구하기 위해 지금까지 제안 된 유일한 실용적인 솔루션입니다. 오늘날 우리가 알고있는 인터넷의 설계자들은 인터넷에서 정보를 검색하는 것은 동의어, 동의어 등 인간이 생각하고 의사 소통하는 방식을 통제하는 근본적인 언어 현상을 다루는 메커니즘을 제공하지 않았기 때문에 거짓의 홍수가 발생합니다 긍정. 시맨틱 웹의 개념은 웹 자원에 명확한 식별자를 할당하는 것으로 귀결되며, 이는 의미를 정확하게 식별하는 데 도움이됩니다. 언젠가 성공한다면 우리는 일반적인 Google 검색이 어떻게 생겼는지 잊어 버릴 수 있습니다. 실패하면 모두 그대로 남아있게됩니다.
{kind=link}
더블린 코어는 정보 자원 간의 관계보다는 정보 자원에 포함 된 내용 (데이터/메타 데이터 관련 데이터)과 관련됩니다. 관계에 대한 정보는 ISO 주제 맵 (http://en.wikipedia.org/wiki/Topic_Maps)을 사용하여 설명 할 수 있습니다. – codeinthehole
시만텍 웹은 분류보다는 데이터 간의 관계에 더 많이 관련되어 있습니다. – codeinthehole
완전성을 위해 예제가 개념을 전달하는 데 종종 도움이되기 때문에 언급 한 언어 중 하나를 사용하여 답변에 작은 코드 예제를 제공 할 수 있습니까? – w5m