1
저는 Python으로 CUDA 및 3D 텍스처를 사용하고 있습니다 (pycuda 사용). Memcpy3D이라는 기능이 있으며 여기에는 Memcpy2D과 몇 가지 추가 기능과 동일한 멤버가 있습니다. 그 안에는 width_in_bytes, src_pitch, src_height, height 및 copy_depth과 같은 것을 설명하기 위해 호출합니다. 이것은 내가 (3D에서) 고심하고 있으며 C 또는 F 스타일 색인 작성과의 관련성입니다. 예를 들어 아래 작업 예제에서 F에서 C로 순서를 변경하면 작업이 중단되고 그 이유는 알 수 없습니다. 우선3D 배열을위한 메모리의 피치, 너비, 높이, 깊이를 설명하십시오.
- 는 I은
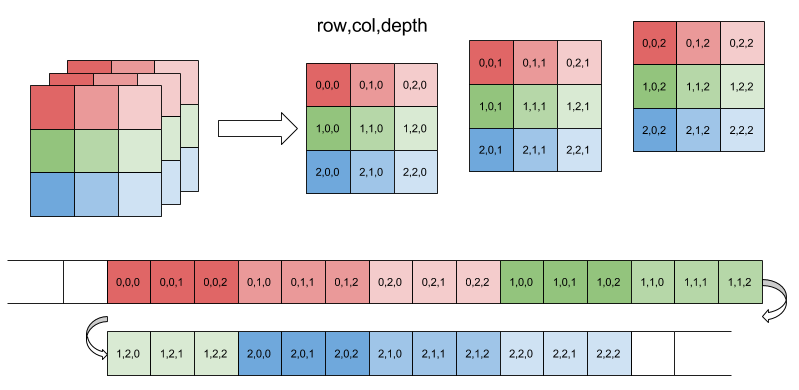
threadIdx.x한 인덱스를 가로 질러 이동하는 데 걸리는 (또는 X 방향 또는 열) 바이트 수를 메모리에 피치를 이해한다. 따라서 C 모양 (3,2,4)의 float32 배열에 대해 x의 값 하나를 이동하려면 4 개의 값을 메모리 (as the indexing goes down the z axis first?)로 옮길 것을 기대합니다. 따라서 내 피치는 4 * 32 비트가됩니다. - 나는 행 수로
height을 이해합니다. (이 예제에서는 3) - 나는 열편의 숫자로
width을 이해합니다. (이 예에서는 2) - 나는
depth을 z 조각의 수로 이해합니다. (이 예에서는 4) width_in_bytes은 그 뒤에있는 z 요소의 ( 포함) 행의 너비 즉, 행 슬라이스 (0, :, :)로 이해합니다. 이것은 y 방향으로 한 요소를 가로 지르는 데 걸리는 메모리의 주소 수입니다.
{kind=link}
그래서 나는 아래의 코드에서 C로 F의 순서를 변경하고 그에 따라 여전히 작동하지 않는 높이/너비 값을 변경하는 코드를 적용 할 때. 단지 논리적 인 실패로 인해 피치, 너비, 높이, 깊이의 개념을 정확하게 이해하지 못한다고 생각하게합니다.
나를 교육 시키십시오.
다음은 배열을 GPU에 텍스처로 복사하고 내용을 다시 복사하는 전체 작업 스크립트입니다.
import pycuda.driver as drv
import pycuda.gpuarray as gpuarray
import pycuda.autoinit
from pycuda.compiler import SourceModule
import numpy as np
w = 2
h = 3
d = 4
shape = (w, h, d)
a = np.arange(24).reshape(*shape,order='F').astype('float32')
print(a.shape,a.strides)
print(a)
descr = drv.ArrayDescriptor3D()
descr.width = w
descr.height = h
descr.depth = d
descr.format = drv.dtype_to_array_format(a.dtype)
descr.num_channels = 1
descr.flags = 0
ary = drv.Array(descr)
copy = drv.Memcpy3D()
copy.set_src_host(a)
copy.set_dst_array(ary)
copy.width_in_bytes = copy.src_pitch = a.strides[1]
copy.src_height = copy.height = h
copy.depth = d
copy()
mod = SourceModule("""
texture<float, 3, cudaReadModeElementType> mtx_tex;
__global__ void copy_texture(float *dest)
{
int x = threadIdx.x;
int y = threadIdx.y;
int z = threadIdx.z;
int dx = blockDim.x;
int dy = blockDim.y;
int i = (z*dy + y)*dx + x;
dest[i] = tex3D(mtx_tex, x, y, z);
}
""")
copy_texture = mod.get_function("copy_texture")
mtx_tex = mod.get_texref("mtx_tex")
mtx_tex.set_array(ary)
dest = np.zeros(shape, dtype=np.float32, order="F")
copy_texture(drv.Out(dest), block=shape, texrefs=[mtx_tex])
print(dest)