3
그래서 컴퓨터를 프록시 using this으로 바꿔주는 프로그램을 만들려고합니다. gzip/deflate 페이지를 제외한 모든 것이 잘 작동합니다.C# - GZipStream 마법 번호가 잘못 되었나요?
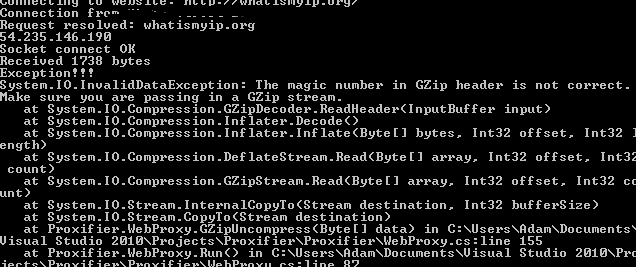
압축을 풀려고 할 때마다 GzipHeader의 마법 번호가 잘못되었다는 InvalidDataException이 발생합니다. 데이터 압축을
private byte[] GZipUncompress(byte[] data)
{
using (var input = new MemoryStream(data))
{
input.Seek(0, SeekOrigin.Begin);
using (var gzip = new GZipStream(input, CompressionMode.Decompress))
using (var output = new MemoryStream())
{
output.Seek(0, SeekOrigin.Begin);
gzip.CopyTo(output);
return output.ToArray();
}
}
}
:
나는이 기능을 사용합니다. 오류 : 어떤 도움을 주시면 감사하겠습니다
error http://gyazo.com/c59de705a264cda47d670ae9b03dfa39.png
{kind=link}
.
EDIT : 어딘가에 얻은 것 같습니다!
usr이 제안했듯이 HTTP 구문 분석기를 작성하여 본문을 가져 와서 압축을 풀어야합니다.
분석하기 전에 : http://pastebin.com/k9e8wMvr
이 내가 몸에 들어갈 때 사용하는 방법입니다 : : 구문 분석 후 http://pastebin.com/Cb0E8WtT
그러나
private byte[] HTTParse(byte[] data)
{
string http = ascii.GetString(data);
char[] lineBreak = crlf.ToCharArray();
string[] parts = http.Split(lineBreak);
List<byte> res = new List<byte>();
for (int i = 1; i < parts.Length; i++)
{
if (i % 2 == 0)
{
Regex r = new Regex(@"(.)*: (.)*");
Regex htt = new Regex(@"HTT(.)*/(.)*.(.)* d{1,50} (.)*");
if (!r.IsMatch(parts[i]) && !htt.IsMatch(parts[i]))
{
//Console.WriteLine("[TEST] " + parts[i]);
res.AddRange(ascii.GetBytes(parts[i]));
res.AddRange(ascii.GetBytes("\r\n"));
}
}
}
return res.ToArray();
}
, 나는 여전히 "마법을 말하는 오류가 GZip 헤더의 숫자가 올바르지 않습니다 .GZip 스트림을 전달하고 있는지 확인하십시오. "
EDIT (2) : 답변을 here에서 복사 한 후 본문을 성공적으로 압축 해제했습니다.
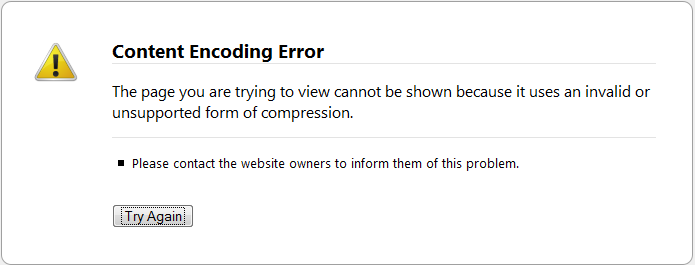
새로운 문제 : Firefox.
error http://gyazo.com/7c40af607471fbdd3c4968af547004b6.png
{kind=link}
나는 ... 지금 내가 잘못 이제 갈
심지어 GZIP 페이지의 압축을 해제 할 필요가 있는지 여부를 확실 해요?
아마도 데이터는 gzip으로 압축되지 않습니다. 바이트를보십시오. 그들은 같은 중요시하는 점은 무엇입니까. – usr
참고 사항 : 새로운'MemoryStream'을 "되감기"할 필요가 없습니다. Seek (0, SeekOrigin.Begin)'은 이중화 –
@usr : http : // pastebin입니다.com/Cb0E8WtT 이것은 whatismyip.org의 요청입니다. 헤더에서 응답을 분리해야하는 것처럼 보입니다. 내가 어떻게 그럴 수 있니? –